支持免费远程部署到你电脑上,无需再担心不会安装的问题!
基于Scrapy爬虫框架高考自愿信息爬虫技术实现与报告
python 高考 有论文 python设计
基于Scrapy高考自愿信息爬虫技术实现,主要包含了代码的实现和报告的详细过程。非常适合Scrapy爬虫框架的学习或做为学生爬虫作业参考项目,由于爬虫目标站的元素改变,可能会导致程序失效,购买之前一定要了解。代码主要实现了https://www.gk100.com/zhiyuan/list_2002.htm的高考志愿信息的抓取,同时会自动进行抓取下一页数据,然后生成excel文件。报告写的非常细,从页面分析到Scrapy框架的创建,以及代码实现。报告近2000多字,可供同学学习,如果有定制需求,可以联系客服人员。
运行环境
- python版本:3.7 及以上
- 开发工具:Pycharm 或 其他
- 编程语言: Python + Scrapy爬虫框架
- 数据库: 无
- 前端:无
- 详细技术:Python+Scrapy+pandans
内容包括
购买的内容主要包括有 项目源码+报告+分析图+免费远程部署安装

主要功能
基于Scrapy高考自愿信息爬虫技术实现
主要包含了代码的实现和报告的详细过程。非常适合Scrapy爬虫框架的学习或做为学生爬虫作业参考项目,由于爬虫目标站的元素改变,可能会导致程序失效,购买之前一定要了解。
代码主要实现了https://www.gk100.com/zhiyuan/list_2002.htm的高考志愿信息的抓取,同时会自动进行抓取下一页数据,然后生成excel文件。报告写的非常细,从页面分析
到Scrapy框架的创建,以及代码实现。报告近2000多字,可供同学学习,如果有定制需求,可以联系客服人员。
设计截图
点击图片可以放大查看



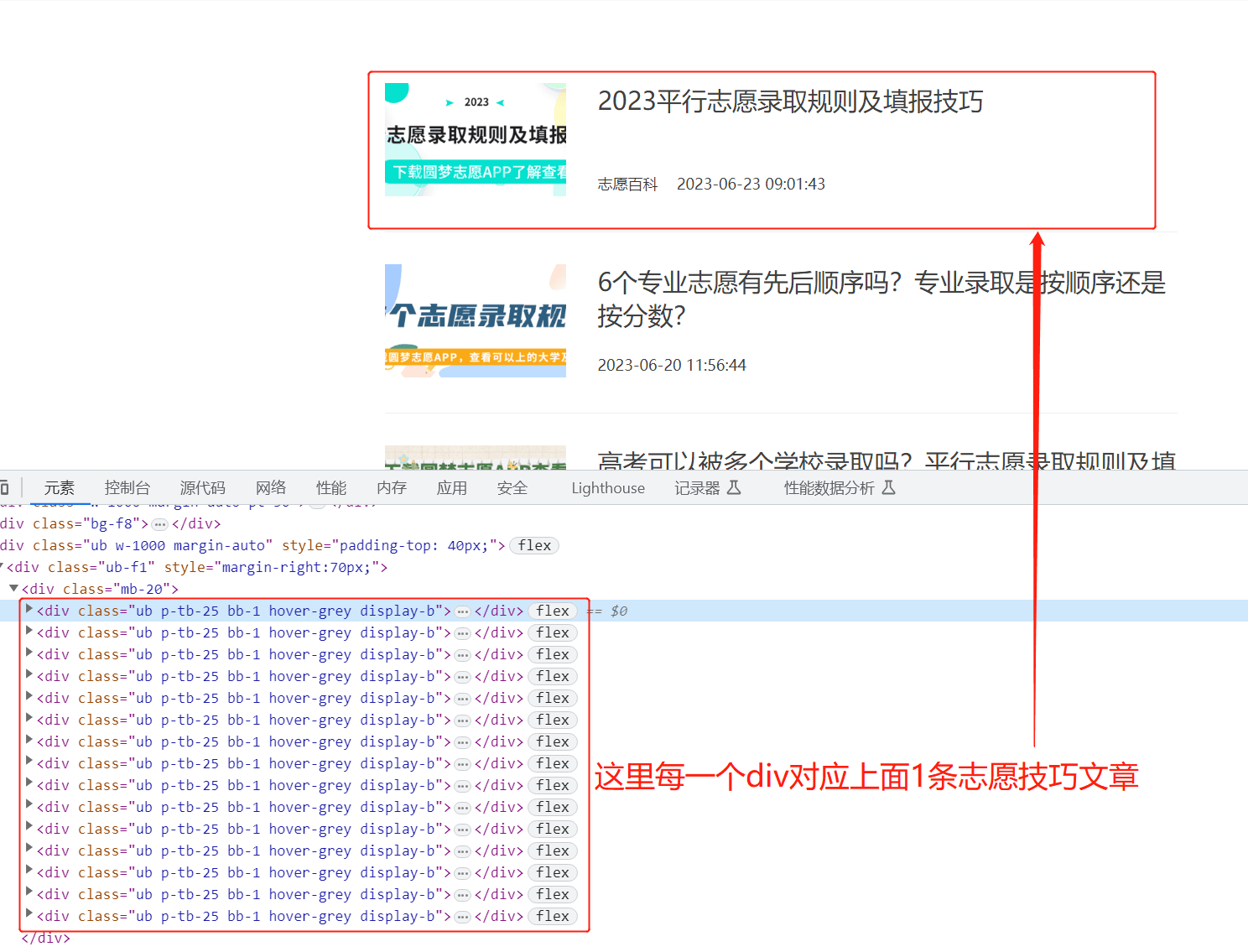
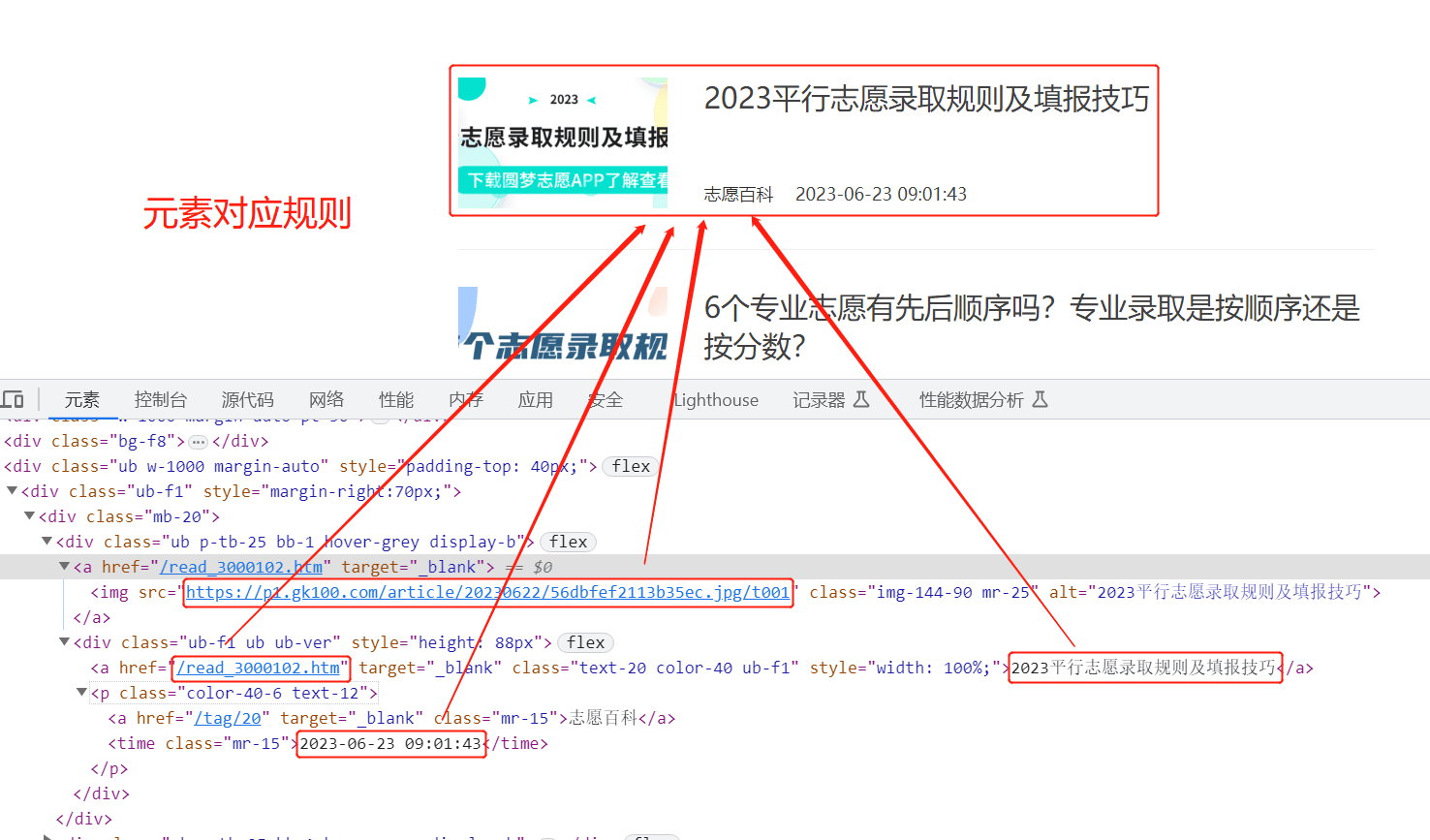
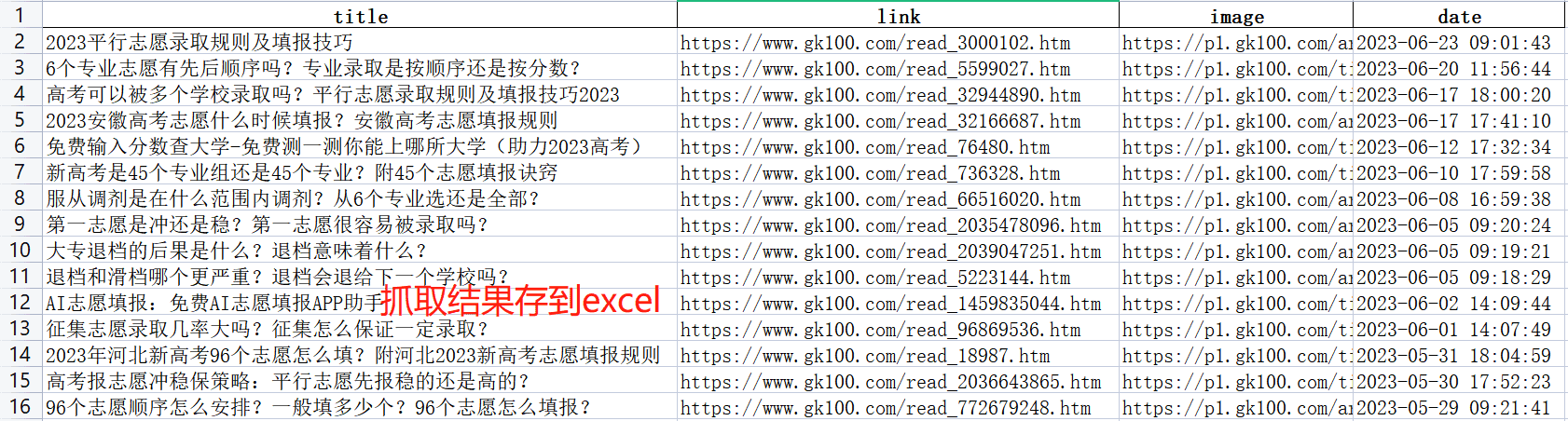
建议全屏和调节清晰度观看效果更佳,演示视频包括项目的主要功能介绍,下载内容介绍,具体的安装教程请下载查看
等待上传